In this article, we focus on an industrial machine learning (ML) application: digitization of the engineering schematic diagram. Schematic diagrams are the bread-and-butter of the industrial engineer, and some examples include piping & instrumentation diagrams (P&IDs), process flow diagrams (PFDs) and isometric diagrams. Here we review common pain points that the industrial engineer faces when working with these diagrams and explain what you can do to alleviate some of these burdens.
1. Brownfield projects have varying image quality
Prior to using CAD (Computer Aided Design) software, engineering schematic diagrams existed on large sheets of paper and were often passed around by engineers during an Engineering & Construction (E&C) project. In the process, the diagrams could have undergone modifications, annotations, and physical wear and tear that were exacerbated when photocopied or scanned. For this reason, brownfield engineering projects (i.e., existing installations) from decades past typically contain poor quality drawing images. For greenfield projects (i.e., “build from scratch”), all the designs can be started in CAD so no issues related to image quality are encountered.
2. Engineering standards are not fixed, hard rules
In P&IDs, PFDs and isometrics, there are common engineering standards, e.g., ISA5.1, with regards to how certain symbols, lines and text appear in a diagram in relation to each other. However, there is much variation in how each process engineer designs these diagrams. This makes it challenging to interpret drawings without legend sheets.
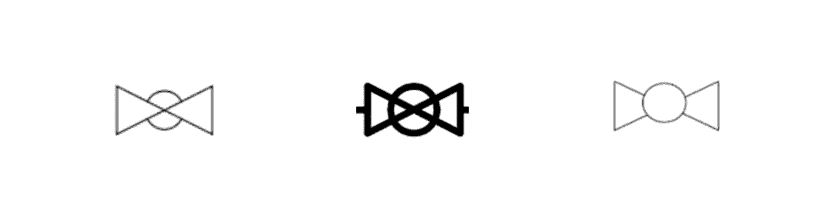
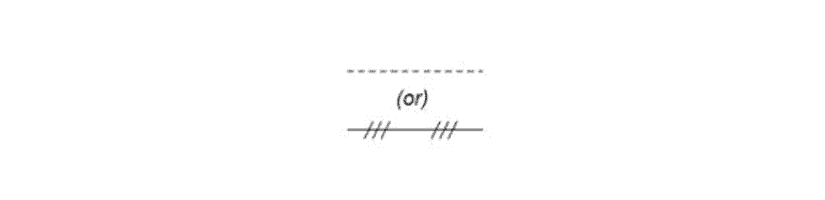
For example, a ball valve in one project might look slightly different in another project (see Figure 1). Similarly, an electrical line can be represented in two different ways (see Figure 2). Additionally, some P&IDs might have valve IDs and sizes located close to the valve, while others have an arrow to associate the valve symbol with its attributes. The existence of multiple standards makes digitization extremely challenging even on diagrams with good image quality.
Figure 1: Three possible representations of a ball valve
Figure 2: Two possible representations of an electrical line
3. Manual work is tiresome
The high variability of symbology and design across engineering schematics make it hard for even an untrained human engineer to read, process and extract information from them. P&IDs are core to an E&C project in various stages from bidding, procurement to construction.
For example, in the bid stage of a project (brownfield or greenfield), one might get paper or raw scanned image copies of thousands of P&IDs. CAD source files are typically not released to bidders in this initial stage before work has been awarded. From this, the bidding team needs to come up with a material take-off (MTO) estimate in order to price the project accurately. The team typically has a limited time window to submit their bid, making it manually burdensome (and infeasible!) to process each and every P&ID.
A second example of how P&IDs are used in E&C is when a specific search needs to be executed across a package of P&IDs, PFDs, isometrics and specification sheets. A project engineer could be faced with the Quality Assurance & Quality Control (QA & QC) task of finding all instances where a particular instrument tag is referred to and/or defined in a project of several thousands of pages. This is, again, quite a manually burdensome task that is error-prone due to human fatigue over time.
A final example of how P&IDs can be used involves benchmarking complexity of historical projects of a specific unit (e.g., a diesel hydrotreater unit or sulphur recovery unit) and using these numbers as guidelines for how current and future projects for that unit are/should be executed. Anything too high or low might serve as a warning to projects that have veered off-track.
Note that the last two examples above are most relevant for brownfield expansion projects since greenfield ones will have diagrams entered in a CAD-like smart software like SmartPlant P&ID. Digitization into a smart CAD format means that counts and types of entities in the diagrams are easily accessible to the engineer.
4. Failure is not an option. Mistakes are unacceptable
In the project bid example described above, the lowest priced bid tends to win, making it crucial for bidders to be as accurate in their estimates as possible. A too-high bid price can result in losing the bid, while a too-low bid price means losing money despite winning work.
In the second project QA & QC example, mistakes could result in re-work in a project (e.g., if the valve width doesn’t match the piping width that it’s connected to), resulting in project delays and decreases in profit margins. Consequences of mistakes include financial loss and reputational risk.
In the final benchmarking example, capturing complexity of historical projects isn’t only time-consuming but also often neglected since forward-looking activities tend to be prioritized. Any kind of historical benchmarking needs to be accurate, else there’s a risk of red-flagging a perfectly acceptable project design/delivery.
Finally, any information extracted from industrial P&IDs should be highly accurate since these diagrams are typically of heavy-asset installations, where safety is critical and cannot be compromised.
5. Machine learning can reduce time & increase accuracy
With such high stakes, it’s important to keep the human engineer at the center of the process and firmly in the driver’s seat. The key is to leverage ML for repetitive tasks that are error-prone for humans, based on the sheer number of instances to be identified. Our approach for obtaining a high fidelity solution to this high-variance, high-stakes engineering problem is to introduce a human-in-the-loop solution that has the human engineer providing inputs / feedback to the system to act/learn upon. This is a must-have for safety-critical environments such as those faced in industrial engineering.